基础知识 #
1.向量 #
向量是数学中一个非常重要的概念,它不仅仅是一个数字,而是同时包含大小和方向的量。
1.1 向量的基本概念 #
想象一下,如果我告诉你"向前走5步",这个指令包含了两个信息:
- 方向:向前
- 大小:5步
这就是向量的本质!向量同时表示"多大"和"往哪个方向"。
1.2 向量的表示方法 #
在坐标系中,我们通常用有序数对来表示向量:
- 二维向量:(x, y)
- 三维向量:(x, y, z)
例如,向量 (3, 4) 表示在x轴方向移动3个单位,在y轴方向移动4个单位。
想象你在操场上:
- 如果你向东走3米,再向北走4米,你的位置变化可以用向量 (3, 4) 表示
- 这个向量的长度(大小)是 $\sqrt{3^2 + 4^2} = 5$ 米
- 方向是从原点指向点 (3, 4) 的方向
2.什么是向量Embeddings #
向量Embeddings(嵌入)是一种将离散对象(如文字、图片、声音等)映射到连续向量空间的技术。
简单来说,它是将难以直接计算的信息"嵌入"到一个数学空间中,使计算机能够处理这些信息。
2.1 简单理解 #
想象一下,如果我们要描述不同的水果:
- 苹果:红色、圆形、甜的
- 香蕉:黄色、弯曲、甜的
- 柠檬:黄色、椭圆形、酸的
我们可以用数字来表示这些特征:
- 颜色:红色=1,黄色=2
- 形状:圆形=1,弯曲=2,椭圆形=3
- 味道:甜=1,酸=2
那么这些水果就可以表示为:
- 苹果:[1,1,1]
- 香蕉:[2,2,1]
- 柠檬:[2,3,2]
这些数字列表就是简单的"嵌入"。计算机可以通过这些数字来理解水果之间的关系,比如香蕉和柠檬都是黄色的,所以它们的第一个数字相同。
3.向量数据库 #
3.1 什么是向量数据库? #
向量数据库是一种特殊的数据库,它不像我们平常用的表格那样存储数据,而是把信息变成一串数字(也就是"向量"),然后存储起来。
想象一下,如果我们要描述一只猫,普通数据库可能会这样记录:
- 名字:咪咪
- 颜色:橙色
- 年龄:3岁
但向量数据库会把"猫"这个概念变成一串数字,比如:[0.1, 0.2, 0.3]。这串数字就代表了"猫"的各种特征。
3.2 向量数据库有什么用? #
最重要的用途就是可以快速找到相似的东西!比如:
- 你拍了一张照片,想找类似的图片
- 你写了一段话,想找相似的文章
- 你听了一首歌,想找风格相近的音乐
3.3 向量数据库是怎么工作的? #
- 转换:首先,把文字、图片等信息转换成数字向量
- 存储:把这些向量存储在数据库中
- 搜索:当你要找东西时,也把你的问题转成向量
- 比较:计算你的问题向量和数据库中所有向量的相似度
- 返回结果:把最相似的结果返回给你
4.milvus #
4.1 Milvus简介 #
4.1.1 Milvus是什么? #
Milvus是一种向量数据库,它是专门设计来存储和搜索大量向量数据的。
4.1.2 为什么Milvus这么流行? #
- 超级快:Milvus可以在几毫秒内从数十亿个向量中找到最相似的向量
- 开源免费:任何人都可以使用它,不需要付费
- 容易使用:即使不是专业程序员也能学会使用它
4.1.3 Milvus能做什么? #
- 图片搜索:上传一张照片,Milvus能找到相似的图片
- 语音识别:说一句话,Milvus能理解你的意思
- 推荐系统:根据你喜欢的电影,推荐你可能喜欢的其他电影
- 智能问答:问一个问题,找到最相关的答案
4.1.4 Milvus是如何工作的? #
- 收集数据:把图片、文字、声音等转换成向量(数字列表)
- 存储向量:把这些向量存储在数据库中
- 快速搜索:当你需要查找相似内容时,Milvus能快速找到最相似的向量
4.2 Milvus的安装 #
4.2.1 下载docker-compose.yml文件 #
C:\>Invoke-WebRequest https://github.com/milvus-io/milvus/releases/download/v2.4.15/milvus-standalone-docker-compose.yml -OutFile docker-compose.yml
docker compose up -d
docker compose ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
milvus-etcd quay.io/coreos/etcd:v3.5.5 "etcd -advertise-cli…" etcd 15 seconds ago Up 10 seconds (health: starting) 2379-2380/tcp
milvus-minio minio/minio:RELEASE.2023-03-20T20-16-18Z "/usr/bin/docker-ent…" minio 15 seconds ago Up 9 seconds (health: starting) 0.0.0.0:9000-9001->9000-9001/tcp
milvus-standalone milvusdb/milvus:v2.4.15 "/tini -- milvus run…" standalone 14 seconds ago Up 8 seconds (health: starting) 0.0.0.0:9091->9091/tcp, 0.0.0.0:19530->19530/tcp
4.2.2 docker-compose.yml文件 #
# 指定Docker Compose文件格式版本为3.5
version: '3.5'
# 定义服务组
services:
# etcd服务配置,用于Milvus的元数据存储
etcd:
# 容器名称设置为milvus-etcd
container_name: milvus-etcd
# 使用coreos的etcd镜像,版本为v3.5.5
image: quay.io/coreos/etcd:v3.5.5
# 设置etcd的环境变量
environment:
# 设置自动压缩模式为revision
- ETCD_AUTO_COMPACTION_MODE=revision
# 设置自动压缩保留1000个版本
- ETCD_AUTO_COMPACTION_RETENTION=1000
# 设置后端存储配额为4GB
- ETCD_QUOTA_BACKEND_BYTES=4294967296
# 设置快照计数为50000
- ETCD_SNAPSHOT_COUNT=50000
# 挂载卷,将本地目录映射到容器内的/etcd目录
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
# 启动命令,配置etcd服务器
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
# 健康检查配置
healthcheck:
# 使用etcdctl检查端点健康状态
test: ["CMD", "etcdctl", "endpoint", "health"]
# 每30秒检查一次
interval: 30s
# 超时时间为20秒
timeout: 20s
# 重试3次
retries: 3
# MinIO服务配置,用于Milvus的对象存储
minio:
# 容器名称设置为milvus-minio
container_name: milvus-minio
# 使用MinIO镜像,指定版本
image: minio/minio:RELEASE.2023-03-20T20-16-18Z
# 设置MinIO的环境变量
environment:
# 设置访问密钥
MINIO_ACCESS_KEY: minioadmin
# 设置密钥
MINIO_SECRET_KEY: minioadmin
# 端口映射,将容器的9001和9000端口映射到主机
ports:
- "9001:9001"
- "9000:9000"
# 挂载卷,将本地目录映射到容器内的/minio_data目录
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
# 启动命令,配置MinIO服务器和控制台地址
command: minio server /minio_data --console-address ":9001"
# 健康检查配置
healthcheck:
# 使用curl检查MinIO健康状态
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
# 每30秒检查一次
interval: 30s
# 超时时间为20秒
timeout: 20s
# 重试3次
retries: 3
# Milvus独立服务配置
standalone:
# 容器名称设置为milvus-standalone
container_name: milvus-standalone
# 使用Milvus镜像,版本为v2.4.15
image: milvusdb/milvus:v2.4.15
# 启动命令,以独立模式运行Milvus
command: ["milvus", "run", "standalone"]
# 安全选项配置
security_opt:
# 禁用seccomp配置文件
- seccomp:unconfined
# 设置Milvus的环境变量
environment:
# 设置etcd端点地址
ETCD_ENDPOINTS: etcd:2379
# 设置MinIO地址
MINIO_ADDRESS: minio:9000
# 挂载卷,将本地目录映射到容器内的/var/lib/milvus目录
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
# 健康检查配置
healthcheck:
# 使用curl检查Milvus健康状态
test: ["CMD", "curl", "-f", "http://localhost:9091/healthz"]
# 每30秒检查一次
interval: 30s
# 启动后等待90秒开始检查
start_period: 90s
# 超时时间为20秒
timeout: 20s
# 重试3次
retries: 3
# 端口映射,将容器的19530和9091端口映射到主机
ports:
- "19530:19530"
- "9091:9091"
# 依赖关系,确保etcd和minio服务先启动
depends_on:
- "etcd"
- "minio"
# 网络配置
networks:
# 默认网络配置
default:
# 网络名称设置为milvus
name: milvus
4.2.3 配置docker镜像 #
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"experimental": false,
"registry-mirrors": [
"https://fwvjnv59.mirror.aliyuncs.com",
"https://docker.m.daocloud.io",
"https://huecker.io",
"https://dockerhub.timeweb.cloud",
"https://noohub.ru"
]
}
4.3 Attu:Milvus的图形界面工具 #
Attu是一个帮助我们使用Milvus向量数据库的图形界面工具
4.3.1 Attu能做什么? #
- 查看数据:看到存储在Milvus中的所有集合(可以理解为表格)和向量数据
- 创建集合:建立新的数据存储空间
- 导入数据:把数据添加到Milvus中
- 搜索相似内容:找到与某个向量最相似的其他向量
- 管理数据库:监控数据库的运行状态和性能
4.3.2 如何使用Attu? #
- 首先确保Milvus已经运行起来了
- 打开网页浏览器,访问Attu的地址(通常是http://localhost:8000)
- 连接到你的Milvus服务器
- 然后你就可以开始浏览和管理你的向量数据了!
4.4 使用Attu连接Milvus #
4.4.1 启动Attu #
docker run -p 8000:3000 -e MILVUS_URL=192.168.2.106:19530 zilliz/attu:v2.5
http://192.168.2.106:8000/#/
这条命令用于启动Attu,它是Milvus向量数据库的图形用户界面工具
1. docker run
- 这是基本的Docker命令,用于创建并启动一个新的容器
2. -p 8000:3000
- 这是端口映射参数
- 将主机的8000端口映射到容器内的3000端口
- 这意味着当你访问主机的8000端口时,请求会被转发到容器内的3000端口
- Attu的Web界面在容器内运行在3000端口
3. -e MILVUS_URL=192.168.2.106:19530
-e表示设置环境变量MILVUS_URL=192.168.2.106:19530指定了Milvus服务器的地址和端口192.168.2.106是Milvus服务器的IP地址19530是Milvus服务的默认端口
4. zilliz/attu:v2.5
- 这是Docker镜像的名称和标签
zilliz/attu是镜像名称,由Zilliz公司(Milvus的开发者)提供v2.5是版本标签,表示使用Attu的2.5版本
5. 访问地址
http://192.168.2.106:8000/#/
这是启动Attu后的访问地址:
http://是协议192.168.2.106是主机IP地址8000是我们映射的端口/#/是Attu应用的路径
简单理解
这个命令做了以下事情:
- 从Docker Hub下载并运行Attu工具(如果本地没有)
- 将Attu连接到指定IP地址的Milvus数据库
- 设置端口映射,让你可以通过浏览器访问Attu的界面
- 提供一个网址,通过这个网址你可以在浏览器中打开Attu管理界面
通过Attu界面,你可以直观地管理Milvus数据库中的向量数据,包括创建集合、导入数据、执行向量搜索等操作,而不需要编写代码。
4.5 创建数据库 #
4.5.1 创建集合 #
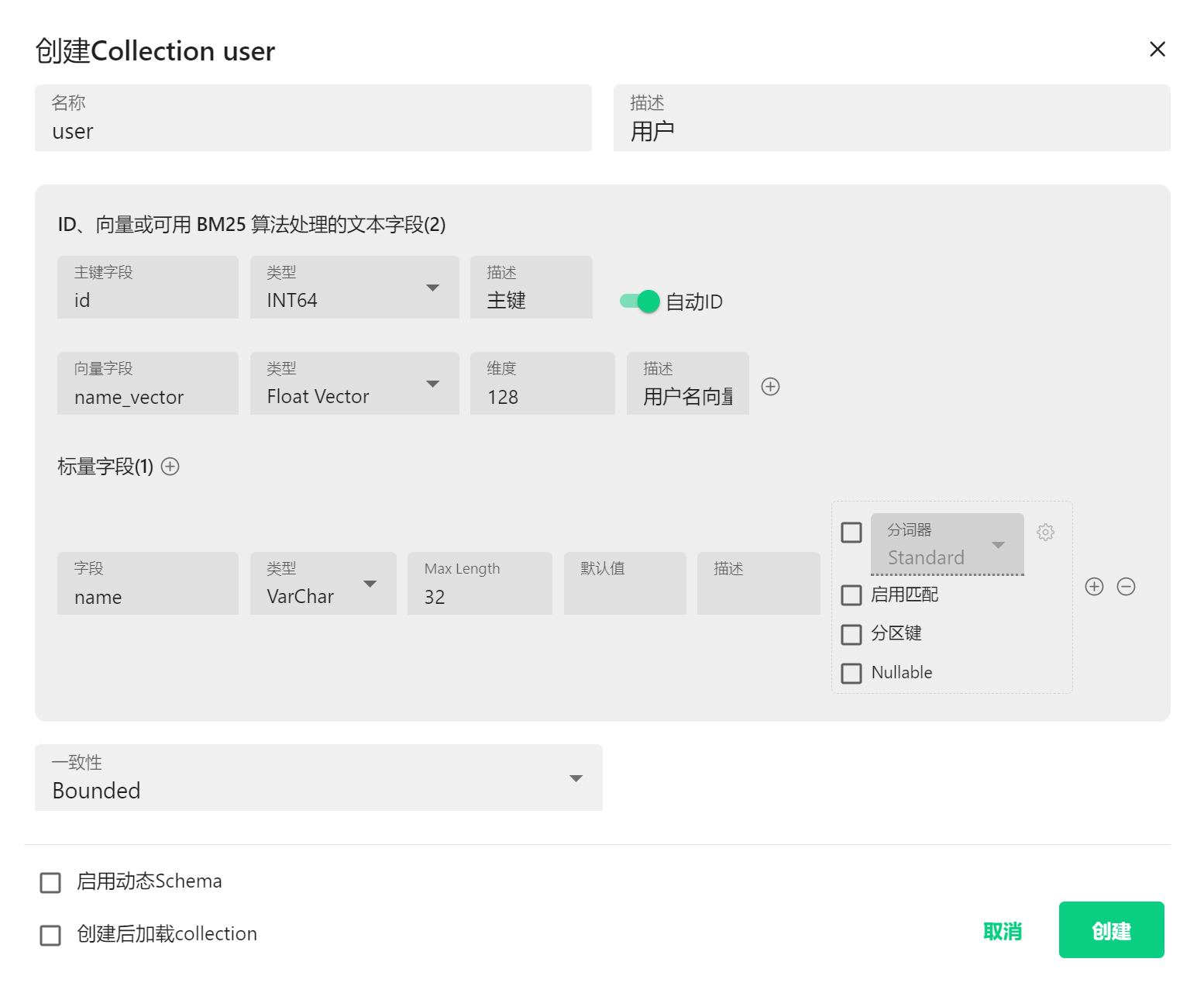
这里展示了在Milvus向量数据库中创建集合(Collection)的界面
基本信息
- 界面标题:创建Collection user
- 集合名称:user
- 集合描述:用户
字段配置 界面显示了三种主要字段类型的配置:
ID字段(主键)
- 字段名称:id
- 数据类型:INT64
- 描述:主键
- 特性:自动ID(已启用)
- 说明:ID
向量字段
- 字段名称:name_vector
- 数据类型:Float Vector
- 维度:128
- 描述:用户名向量
- 功能:用于存储向量数据,支持向量相似度搜索
标量字段
- 字段名称:name
- 数据类型:VarChar
- 最大长度:32
- 分词器:Standard(标准分词器)
- 可选配置:
- 启用匹配(未选中)
- 分区键(未选中)
- Nullable(未选中)
集合属性设置
- 一致性模式:Bounded(有界一致性)
- 其他选项:
- 启用动态Schema(未选中)
- 创建后加载collection(未选中)
4.5.2 分词器 (Standard) #
分词器是用来将文本分解成单个词语的工具。比如"我喜欢编程"可以被分解为"我"、"喜欢"、"编程"。
Standard分词器是最基本的分词方式,它按照一定规则把文本切分成词语,这样在搜索时就能更准确地找到包含特定词语的内容。
4.5.3 启用匹配 #
启用匹配功能让数据库可以进行相似度查询。比如当你搜索"电脑"时,也能找到包含"计算机"的记录。 这就像是你在搜索引擎中输入关键词,即使不是完全一样的词,也能找到相关内容。
4.5.4 分区键 #
分区键用来将大量数据分散存储在不同的服务器上。 想象一下,如果你有一本很厚的字典,可以按照字母A-Z分成26个小册子,这样查找时就不用翻整本书了。分区键就是决定数据应该放在哪个"小册子"里的标准。
4.5.5 Nullable #
Nullable表示这个字段可以为空。就像填表格时,有些项目是必填的(不能为空),有些是选填的(可以为空)。如果勾选了Nullable,就意味着这个字段可以不填写任何值。
4.5.6 一致性 (Bounded) #
Milvus创建集合时的四种一致性选项
在Milvus数据库创建集合时,有四种一致性选项,我们可以用简单的例子来理解:
4.5.6.1 Strong(强一致性) #
这就像是班级里的实时通讯系统。当老师发布一条通知后,所有同学必须立即收到并确认,老师才会继续下一步。这种方式最可靠,但速度较慢,因为要等待每个人都确认。
例子:小明存了100元到银行,如果使用强一致性,那么无论他在哪个ATM机查询,都能立即看到准确的余额。
4.5.6.2 Session(会话一致性) #
这像是你和好友的私聊。你发的消息,你的好友一定能按顺序收到,但其他同学可能暂时看不到或顺序不同。
例子:小红在网上商城下单后,在她自己的账号中能立即看到订单信息,但商城的总销量统计可能要稍后才会更新。
4.5.6.3 Bounded(有界一致性) #
这像是学校的公告栏。老师贴出通知后,同学们会在一定时间内(比如10分钟)都能看到,但不要求立即。
例子:小华发了一条朋友圈,系统保证在5秒内,他的所有好友都能看到这条动态,但不一定是同一时刻看到。
4.5.6.4 Eventually(最终一致性) #
这像是口口相传的消息。信息最终会传到每个人那里,但可能需要较长时间,且不保证具体何时。
例子:图书馆新增了一本书,系统会在某个时间点更新书目清单,但不保证具体何时完成,可能是几分钟,也可能是几小时。
4.5.6.5 如何选择? #
- 需要数据绝对准确时(如银行交易)→ 选Strong
- 需要用户看到自己操作的结果时 → 选Session
- 需要在一定时间内保证一致性 → 选Bounded
- 对时间要求不高,但希望系统运行更快 → 选Eventually
不同的一致性选项就像是在"速度"和"准确性"之间做平衡,根据你的实际需求来选择最合适的一种。
4.6 schema #
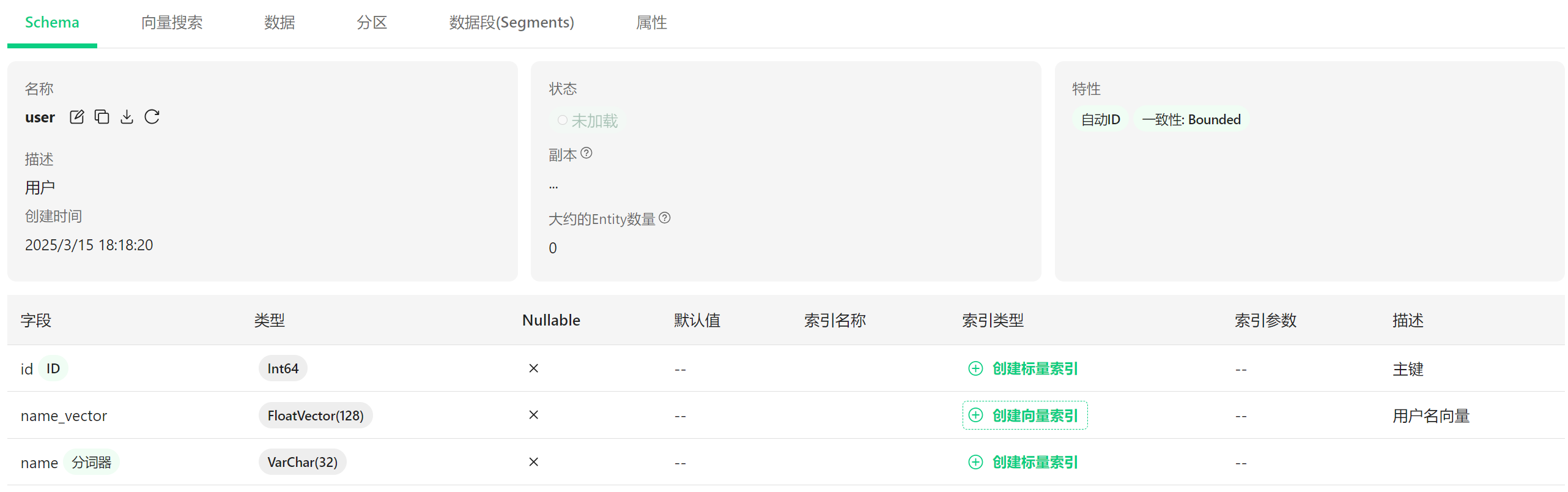
顶部有几个选项卡:Schema(当前页面)、向量搜索、数据、分区、数据段和属性。
4.6.1 集合基本信息 #
- 名称:user(用户)
- 描述:用户
- 创建时间:2023年3月15日 18:18:20
- 状态:未加载(表示数据还没有加载到内存中)
- 副本:1
- 大约的Entity数量:0(表示集合中还没有数据)
4.6.2 集合特性 #
- 自动ID:已启用(系统会自动生成ID)
- 一致性:Bounded(有界一致性,这是数据一致性的一种模式)
4.6.3 字段信息 #
集合包含三个字段:
id
- 类型:Int64(64位整数)
- 不可为空(Nullable: ×)
- 是主键(ID)
- 可以创建标量索引
name_vector
- 类型:FloatVector(128)(128维浮点向量)
- 不可为空
- 可以创建向量索引
- 描述:用户名向量
name
- 类型:VarChar(32)(最多32个字符的可变长度字符串)
- 不可为空
- 使用分词器
- 可以创建标量索引
- 描述:(未显示,但应该是用户名)
4.6.4 简单理解 #
想象一下,这就像是一个特殊的表格:
- 每行代表一个用户
- id列存储用户编号
- name列存储用户名
- name_vector列存储用户名转换成的128个数字(这些数字可以帮助系统快速找到相似的用户名)
这种结构特别适合做"相似搜索",比如找到名字相似的用户,或者根据某些特征找到相似的用户。
4.7 创建索引 #
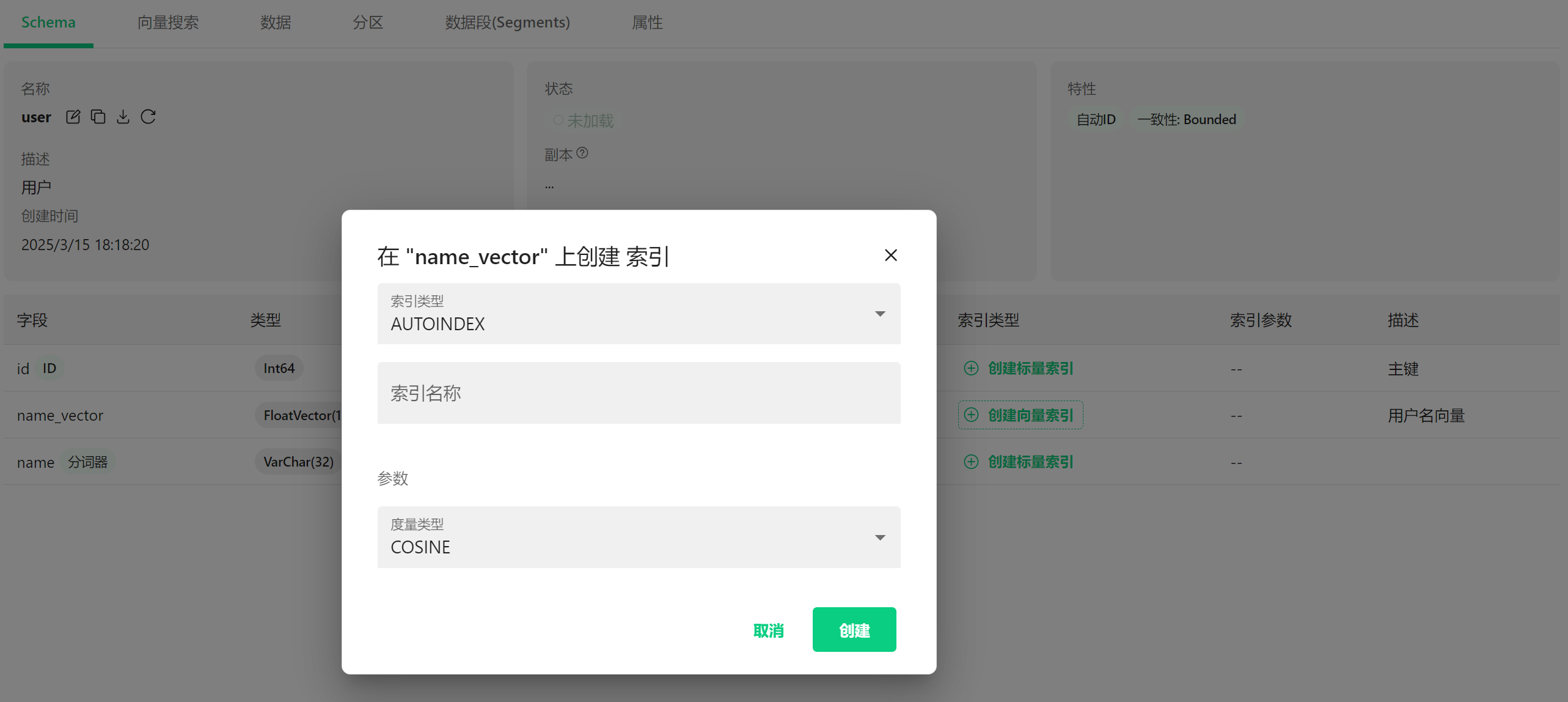
4.7.1 什么是索引? #
想象一下,索引就像是一本书的目录。如果没有目录,你想找某个内容就必须从头到尾翻阅整本书。有了目录,你可以快速找到你想要的内容在哪一页。
在数据库中,索引也是这样工作的,它帮助计算机快速找到你要的数据。
4.7.2 索引创建界面 #
这个弹窗显示我们正在为"name_vector"字段(也就是用户名的向量表示)创建索引:
索引类型:AUTOINDEX
- 这是一种自动选择最适合的索引类型的方式
- Milvus会根据你的数据特点自动选择最合适的索引结构
索引名称:
- 这里可以输入索引的名字(图中是空白的,会使用默认名称)
参数设置:
- 度量类型:COSINE(余弦相似度)
- 这决定了如何计算两个向量之间的"距离"或"相似度"
4.8 加载数据 #
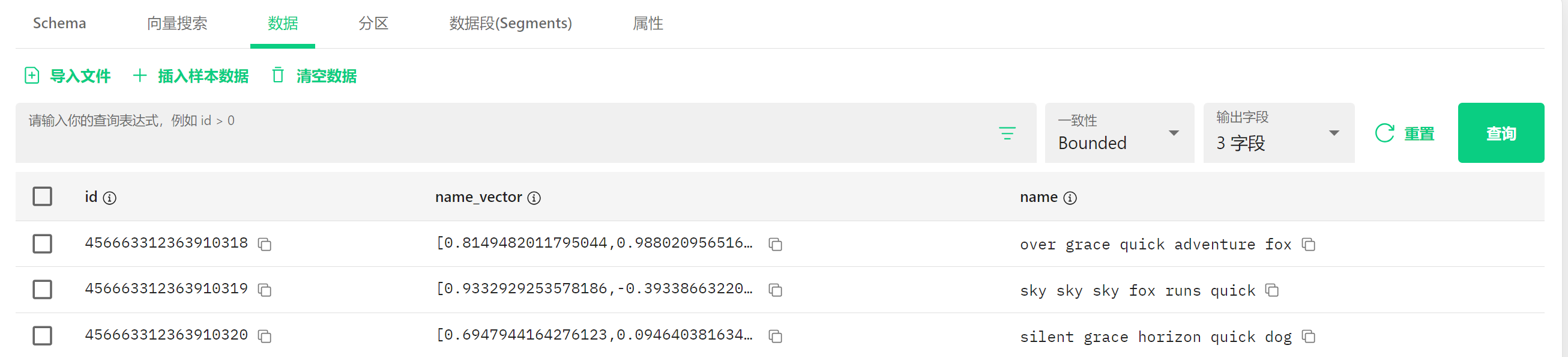
顶部有几个选项卡:Schema、向量搜索、数据(当前页面)、分区、数据段和属性。 在数据选项卡下,你可以看到几个操作按钮:
- 导入文件:从文件中导入数据
- 插入样本数据:添加示例数据
- 清空数据:删除所有数据
4.8.1 查询区域 #
有一个输入框,提示"请输入你的查询表达式,例如 id > 0",这里可以输入条件来筛选数据。
4.8.2 数据显示 #
表格显示了集合中的数据,包含三列:
- id:用户的唯一标识符(一串数字)
- name_vector:用户名的向量表示(一组数字)
- name:用户名文本
4.8.3 具体数据 #
表格中显示了三条记录:
第一行:
- id: 456663312363910318
- name_vector: [0.8149482011795044, 0.9880209565... (一组数字)]
- name: over grace quick adventure fox
第二行:
- id: 456663312363910319
- name_vector: [0.9332929253578186, -0.3933866322... (一组数字)]
- name: sky sky sky fox runs quick
第三行:
- id: 456663312363910320
- name_vector: [0.6947944164276123, 0.0946403816... (一组数字)]
- name: silent grace horizon quick dog
4.8.4 简单理解 #
这个界面就像是一个特殊的表格,显示了数据库中存储的用户信息:
- 每个用户有一个ID号
- 每个用户名被转换成了一串数字(向量),这些数字捕捉了文本的特征
- 原始的用户名文本也被保存下来
这些向量数据使得系统可以快速找到相似的用户名,比如都包含"fox"或"quick"的用户名可能在向量空间中距离较近。
4.8.5 加载集合 #
在Milvus中,必须先加载(load)集合到内存,才能创建和使用索引。这是Milvus的工作机制,让我详细解释一下。
4.8.5.1 为什么需要加载集合? #
Milvus采用了内存计算的架构:
- 数据存储在磁盘上
- 但搜索、索引等操作需要在内存中进行
- 加载操作就是将集合数据从磁盘读入内存
4.8.5.2 Milvus集合生命周期管理 #
在Milvus中,集合有几种状态:
已创建但未加载:
- 集合存在于磁盘上
- 不能进行搜索或索引操作
- 占用最少资源
已加载:
- 集合数据在内存中
- 可以进行所有操作(搜索、索引等)
- 占用内存资源
已释放:
- 集合数据从内存中释放
- 回到"未加载"状态
- 释放内存资源
4.8.5.3 集合加载与释放的最佳实践 #
何时加载集合
- 创建/修改索引前:必须先加载集合
- 执行搜索操作前:必须先加载集合
- 插入大量数据前:加载可提高插入性能
何时释放集合
- 长时间不使用时:释放不活跃的集合以节省内存
- 系统内存压力大时:释放不重要的集合
- 维护操作完成后:如索引创建完成后
4.9 向量搜索 #
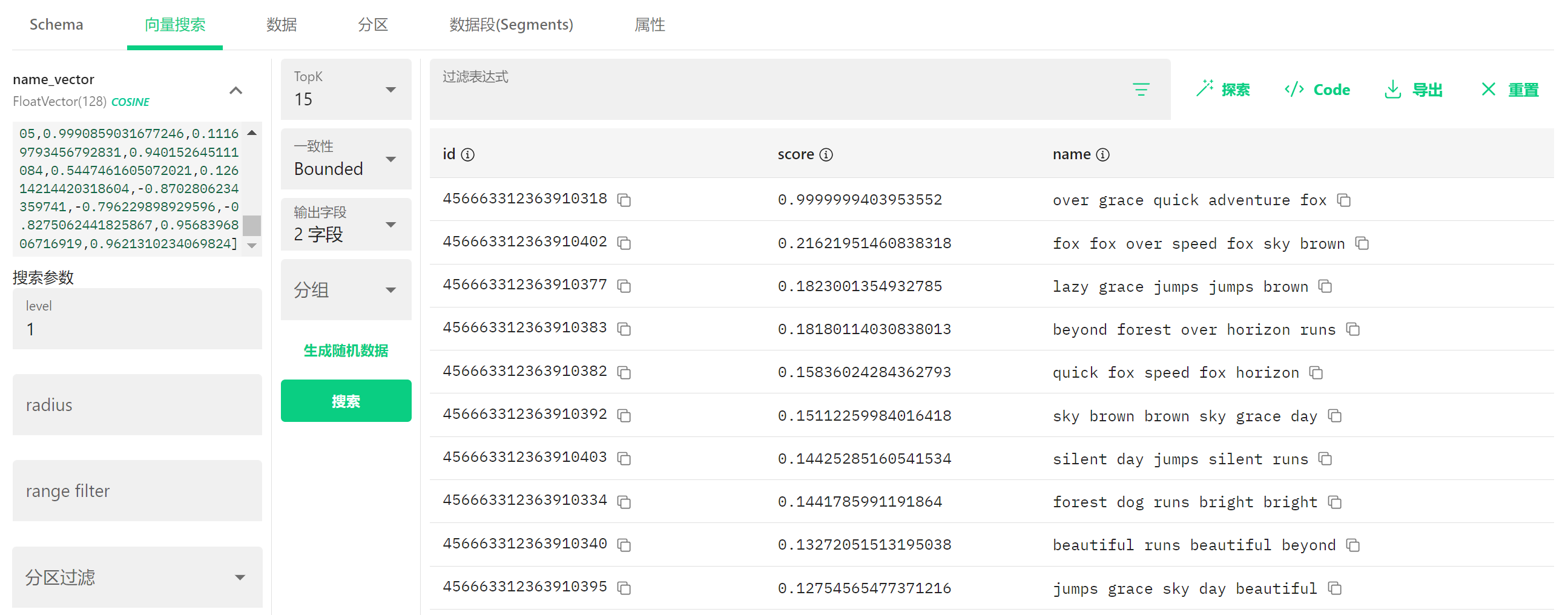
4.9.1 什么是向量搜索? #
向量搜索就像是在说:"给我找一些和这个例子很像的东西!"在这个例面中,我们是在寻找与某个输入向量相似的用户名。
4.9.2 界面左侧(搜索条件) #
搜索向量:
- 顶部显示了一个向量:[0.9990859031677246, 0.1116979345679283, ...]
- 这是我们要查找相似内容的"样本"
搜索参数:
- TopK:15(表示要返回最相似的15条结果)
- 一致性:Bounded(搜索的一致性模式)
- 输出字段:2个字段(选择显示哪些字段)
- 分组:(未选择)
- 搜索参数:
- level:1(搜索精度级别)
- radius:(未设置)
- range filter:(未设置)
- 分区过滤:(未设置)
4.9.3 界面右侧(搜索结果) #
搜索结果显示了与输入向量最相似的用户名,按相似度(score)从高到低排序:
第一行:
- id: 456663312363910318
- score: 0.9999999403953552(几乎完全匹配!)
- name: over grace quick adventure fox
第二行:
- id: 456663312363910402
- score: 0.2162195146083818
- name: fox fox over speed fox sky brown
第三行:
- id: 456663312363910377
- score: 0.1823001354932785
- name: lazy grace jumps jumps brown
...以此类推,显示了更多结果。
4.9.4 简单理解 #
想象一下,这就像是一个"相似度查找器":
- 你给系统一个例子(这里是一组数字,代表某种文本特征)
- 系统会在数据库中寻找最相似的内容
- 结果按照相似度排序显示出来
你可以看到第一个结果的相似度分数接近1.0,这意味着它几乎与搜索向量完全匹配。其他结果的相似度逐渐降低。
4.9.5 搜索参数 #
4.9.5.1 Level(搜索精度级别) #
Level参数是控制搜索精度和速度平衡的关键:
什么是Level?
- Level是一个整数值,通常从1到100
- 现在设置为1
Level的作用:
- 低Level值(如1-2):搜索速度快,但可能会漏掉一些相似结果
- 高Level值(如50-100):搜索更精确,找到更多相似结果,但速度较慢
生活中的例子: 想象你在找一本书。Level=1就像快速扫一眼书架,只看书脊;Level=100就像仔细检查每本书的内容。
4.9.5.2 Radius(搜索半径) #
Radius参数定义了在向量空间中搜索的范围:
什么是Radius?
- 它是一个浮点数,表示向量空间中的距离
Radius的作用:
- 只返回与查询向量距离小于radius的结果
- 即使设置了TopK=15,如果只有3个结果在radius范围内,也只会返回这3个结果
生活中的例子: 想象你站在一个点,说"我只想知道5公里范围内的所有餐厅",这里的"5公里"就是radius。
4.9.5.3 Range Filter(范围过滤器) #
Range Filter参数允许我们根据向量距离进行更精细的过滤:
什么是Range Filter?
- 它是一个表达式,定义了接受结果的距离范围
Range Filter的作用:
- 可以设置最小和最大距离
- 例如:"distance >= 0.5 && distance <= 0.9"
- 这会只返回距离在0.5到0.9之间的结果
生活中的例子: 想象你在找房子,说"我想要离学校不少于500米(避免噪音),但不超过2公里(方便接送)的房子"。
4.9.5.4 分区过滤 #
Milvus中的"分区过滤"功能是向量搜索中另一个非常重要的参数,它可以帮助我们更高效地组织和搜索数据。
4.9.5.4.1 什么是分区(Partition)? #
在理解分区过滤前,我们先要知道什么是分区:
- 分区就像是把一个大书柜分成几个小书架
- 每个分区包含一部分数据,有自己的名称
- 例如,我们可以按照主题将用户数据分为"学生"、"教师"、"家长"等不同分区
4.9.5.4.2 分区过滤是什么? #
分区过滤允许我们只在特定的分区中进行搜索:
- 看到有一个"分区过滤"的下拉菜单(当前未选择任何分区)
- 当你选择特定分区后,搜索只会在那些分区中进行
4.9.5.4.3 生活中的例子 #
想象一个大型超市:
- 超市被分为不同区域:蔬果区、肉类区、日用品区等
- 如果你只想买水果,你只需要去蔬果区寻找
- 这就是"分区过滤"的概念 - 你限制了搜索范围
4.9.5.4.4 如何使用分区过滤? #
创建分区:
- 首先需要创建有意义的分区(例如,按用户类型、地区、活跃度等)
- 每个分区有唯一的名称
插入数据时指定分区:
- 添加新数据时,指定它属于哪个分区
搜索时应用分区过滤:
- 在搜索界面选择要搜索的分区
- 可以选择一个或多个分区
4.9.5.4.6 分区过滤与其他参数的配合 #
分区过滤可以与我们之前讨论的参数一起使用:
分区过滤 + TopK: "在'学生'分区中找出最相似的15个用户"
分区过滤 + Radius: "在'北京'分区中找出相似度超过0.8的所有用户"
分区过滤 + Level: "在'VIP用户'分区中进行高精度搜索"
4.9 分区 #

4.9.1 什么是数据库分区? #
数据库分区就像是把一个大书柜分成几个小格子,这样可以让我们更容易找到和管理书籍。在计算机中,当我们有大量数据时,把它们分成几个区域可以让电脑更快地查找和处理这些数据。
4.9.2 界面中的内容: #
顶部菜单栏:有"Schema"、"向量搜索"、"数据"、"分区"、"数据段"和"属性"等选项,现在选中的是"分区"选项卡。
功能按钮:
- "创建分区":可以新建一个数据分区
- "导入文件":可以从外部导入数据
- "drop":可以删除分区
分区列表:
- 目前只有一个分区,名为"Default partition"
- ID是一串数字:456663312362905661
- 这个分区包含100个"大约Entity数量"
- 创建时间是2025年3月15日18:18:20
4.9.3 为什么需要分区? #
想象一下,如果你有一个装满各种物品的大箱子,找东西会很麻烦。但如果你把物品分类放在不同的小盒子里,比如文具一个盒子、玩具一个盒子,找东西就会快很多。
数据库分区也是这个道理,它帮助计算机更高效地管理和查找大量数据,特别是当数据量非常大的时候。
这种技术在许多需要处理大量信息的场合都很重要,比如网上商店、社交媒体平台或学校的学生信息系统等。
4.10 数据段 #

4.10.1 什么是数据段? #
数据段就像是数据库中存储数据的小容器。想象一下,如果数据库是一个图书馆,分区就是不同的书架区域,而数据段则是书架上的具体书籍盒子,里面装着实际的数据。
4.10.2 界面中的内容: #
顶部菜单栏:有"Schema"、"向量搜索"、"数据"、"分区"、"数据段"和"属性"等选项,现在选中的是"数据段"选项卡。
功能按钮:
- "压缩(Compact)":可以压缩数据段,让它占用更少空间
- "落盘(Flush)":把内存中的数据写入到硬盘上保存
- "刷新":更新显示最新的数据段信息
数据段信息:
- ID:456663312364110319(这是数据段的唯一标识符)
- Level:L1(这表示数据段的层级)
- 分区ID:456663312362905661(这个数据段属于哪个分区)
- 持久数据段状态:Flushed(表示数据已经保存到硬盘上)
- 行数:100(这个数据段包含100行数据)
- 查询节点IDs:1(可能表示哪些节点可以查询这个数据段)
- 查询数据段状态:Sealed(表示这个数据段已经封闭,不能再添加新数据)
4.10.3 为什么需要了解数据段? #
在处理大量数据时,数据库需要有效地组织这些数据。数据段帮助数据库系统更好地管理数据,使得查询和处理数据更快。
就像你整理笔记本一样,把相关的内容放在一起,并且标记好每个部分,这样以后查找时就会更容易。数据段就是数据库用来"整理笔记"的方式。
这些概念虽然看起来复杂,但它们的目的很简单:让计算机能够更快、更有效地存储和查找大量信息。
4.10.4 什么是查询节点ID #
查询节点ID是指在分布式数据库系统中,负责处理查询请求的服务器或计算单元的唯一标识符。让我用简单的方式来解释:
4.10.4.1 简单理解查询节点 #
想象一个大型图书馆,有很多工作人员(节点)分布在不同的楼层和区域:
- 每个工作人员都有自己的工号(节点ID)
- 每个工作人员负责管理特定书架上的图书(数据段)
- 当你需要查找一本书时,你的请求会被分配给负责那个区域的工作人员
4.10.4.2 含义 #
"查询节点IDs: 1" 表示:
- 这个数据段(ID为456663312364110319)目前被分配给了ID为1的查询节点
- 只有这一个节点(节点1)负责处理对这个数据段的查询请求
- 如果有人想查询这个数据段中的信息,请求会被路由到节点1处理
4.10.4.3 类比 #
这就像学校的分组学习:
- 每个小组有一个编号(节点ID)
- 每个小组负责研究特定的知识点(数据段)
- 当老师提问某个知识点时,相应的小组就负责回答(处理查询)
4.11 属性 #
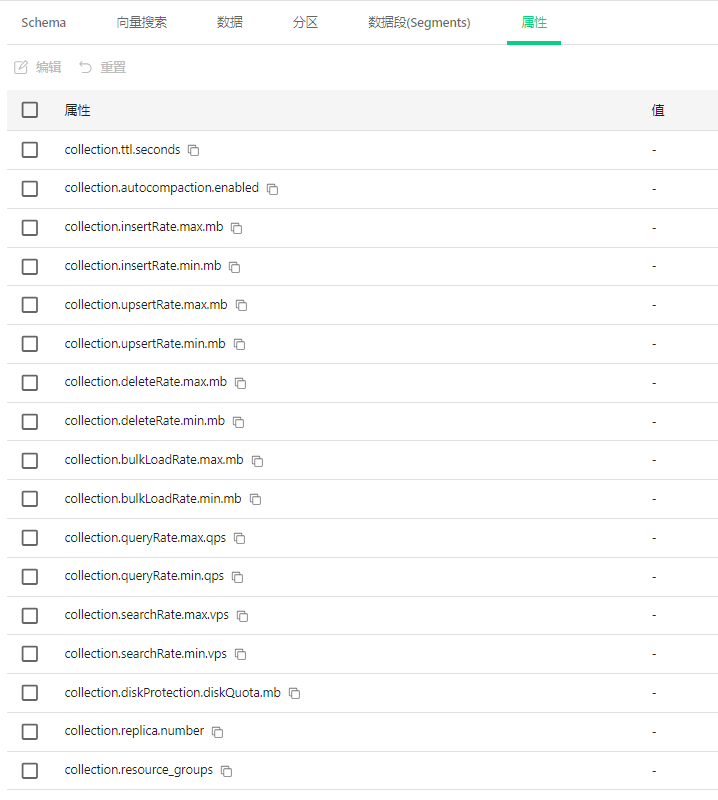
4.11.1 什么是集合属性? #
集合属性就像是对数据库的"规则设定",它们控制着数据库如何处理数据、多快处理数据,以及使用多少资源。这些设置对于数据库的性能和稳定性非常重要。
4.11.2 界面中的属性列表 #
属性都以"collection."开头,表示这些是针对当前集合的设置:
collection.ttl.seconds
- 这是"生存时间"设置,决定数据在集合中保存多长时间
- 如果设置了这个值,超过这个时间的数据会被自动删除
collection.autocompaction.enabled
- 控制是否启用自动压缩功能
- 压缩可以减少存储空间并提高查询效率
数据操作速率限制:
- collection.insertRate.max.mb 和 min.mb:插入数据的最大和最小速率
- collection.upsertRate.max.mb 和 min.mb:更新插入的最大和最小速率
- collection.deleteRate.max.mb 和 min.mb:删除数据的最大和最小速率
- collection.bulkLoadRate.max.mb 和 min.mb:批量加载的最大和最小速率
查询速率限制:
- collection.queryRate.max.qps 和 min.qps:普通查询的最大和最小每秒查询数
- collection.searchRate.max.qps 和 min.qps:向量搜索的最大和最小每秒查询数
资源管理:
- collection.diskProtection.diskQuota.mb:磁盘配额,限制集合可以使用的磁盘空间
- collection.replica.number:副本数量,用于数据备份和负载均衡
- collection.resource_groups:资源组设置,控制集合可以使用的计算资源
4.操作milvus数据库 #
@zilliz/milvus2-sdk-node是Milvus向量数据库的Node.js客户端SDK,让开发者能够在JavaScript/TypeScript项目中轻松操作Milvus数据库
4.1 连接数据库 #
// 导入Milvus客户端库
const { MilvusClient } = require('@zilliz/milvus2-sdk-node');
// 创建Milvus客户端实例,配置连接地址和超时时间
const milvusClient = new MilvusClient({
address: 'localhost:19530',
timeout: 10000,
});
// 定义异步函数用于测试与Milvus服务器的连接
async function testConnection() {
try {
// 获取所有数据库列表
const { db_names } = await milvusClient.listDatabases();
// 输出可用的数据库列表
console.log('可用数据库列表:', db_names);
// 输出连接成功的消息
console.log('连接成功:已成功连接到Milvus服务器');
// 返回连接成功的状态
return true;
} catch (error) {
// 捕获并输出连接错误信息
console.error('连接失败:无法连接到Milvus服务器', error.message);
// 返回连接失败的状态
return false;
} finally {
// 无论成功与否,最终都关闭与Milvus的连接
await milvusClient.closeConnection();
// 输出关闭连接的消息
console.log('已关闭与Milvus服务器的连接');
}
}
// 调用测试连接函数
testConnection()
// 捕获并处理执行过程中的错误
.catch(error => {
// 输出执行测试连接函数时的错误信息
console.error('执行测试连接函数时出错:', error);
// 以错误状态退出进程
process.exit(1);
});
4.2 管理数据库 #
// 导入Milvus客户端库
const { MilvusClient } = require('@zilliz/milvus2-sdk-node');
// 创建Milvus客户端实例,配置连接地址和超时时间
const milvusClient = new MilvusClient({
address: 'localhost:19530',
timeout: 10000
});
// 使用立即执行的异步函数
(async function () {
try {
// 获取所有数据库列表
const { db_names } = await milvusClient.listDatabases();
console.log('当前数据库列表:', db_names);
// 检查目标数据库是否已存在
const dbExists = db_names.includes('my_database');
if (!dbExists) {
// 如果数据库不存在,则创建新数据库
await milvusClient.createDatabase({
db_name: 'my_database'
});
console.log('数据库创建成功: my_database');
} else {
// 如果数据库已存在,则跳过创建步骤
console.log('数据库已存在: my_database,跳过创建步骤');
}
// 切换到目标数据库
await milvusClient.useDatabase({
db_name: 'my_database'
});
console.log('已成功切换到数据库: my_database');
} catch (error) {
// 捕获并处理可能出现的错误
console.error('操作失败:', error.message);
} finally {
// 无论成功与否,最终都关闭数据库连接
await milvusClient.closeConnection();
console.log('已关闭与Milvus服务器的连接');
// 退出程序
process.exit(0);
}
})();
4.3 Schema管理 #
// 导入Milvus客户端库和数据类型定义
const { MilvusClient, DataType } = require('@zilliz/milvus2-sdk-node');
// 创建Milvus客户端实例,配置连接地址
const milvusClient = new MilvusClient({
address: 'localhost:19530',
});
// 使用立即执行的异步函数创建用户集合
(async function createUserCollection() {
try {
// 切换到指定的数据库
await milvusClient.useDatabase({
db_name: 'my_database'
});
// 定义集合的结构模式
const collectionSchema = {
// 设置集合名称
collection_name: 'user_collection',
// 定义集合的字段列表
fields: [
{
// 定义ID字段
name: 'id',
// 设置数据类型为64位整数
data_type: DataType.Int64,
// 设置为主键
is_primary_key: true,
// 禁用自动生成ID
autoID: false
},
{
// 定义名称字段
name: 'name',
// 设置数据类型为可变长度字符串
data_type: DataType.VarChar,
// 设置最大长度为128个字符
max_length: 128
},
{
// 定义特征向量字段
name: 'feature_vector',
// 设置数据类型为浮点向量
data_type: DataType.FloatVector,
// 设置向量维度为3
dim: 3
}
],
// 设置集合的描述信息
description: '用户信息集合'
};
// 创建集合
await milvusClient.createCollection(collectionSchema);
// 输出创建成功的消息
console.log('集合创建成功');
// 获取所有集合的列表
const { collection_names } = await milvusClient.listCollections();
// 输出集合列表
console.log('集合列表:', collection_names);
} catch (error) {
// 捕获并处理可能出现的错误
console.error('操作失败:', error.message);
} finally {
// 无论成功与否,最终都关闭数据库连接
await milvusClient.closeConnection();
// 退出程序
process.exit(0);
}
})();
4.4 索引管理 #
// 导入Milvus客户端库
const { MilvusClient } = require('@zilliz/milvus2-sdk-node');
// 创建Milvus客户端实例,配置连接地址和超时时间
const milvusClient = new MilvusClient({
address: 'localhost:19530',
timeout: 10000,
});
// 使用立即执行的异步函数管理索引
(async function manageIndexes() {
try {
// 切换到指定的数据库
await milvusClient.useDatabase({
db_name: 'my_database'
});
// 检查集合是否存在
const { value: collectionExists } = await milvusClient.hasCollection({
collection_name: 'user_collection'
});
// 如果集合不存在,则退出函数
if (!collectionExists) {
console.log('集合不存在,跳过创建索引步骤');
return;
}
// 输出集合存在的确认信息
console.log('集合存在: 已确认');
// 初始化索引存在状态为false
let indexExists = false;
try {
// 输出检查索引状态的信息
console.log('检查索引状态...');
// 获取索引信息
const indexInfo = await milvusClient.describeIndex({
collection_name: 'user_collection',
field_name: 'feature_vector'
});
// 判断索引是否存在
indexExists = indexInfo?.index_descriptions?.length > 0;
} catch (error) {
// 捕获并输出检查索引时的错误
console.log('检查索引时出错:', error.message);
}
// 输出索引存在状态
console.log('索引存在:', indexExists);
// 如果索引已存在,则跳过创建步骤
if (indexExists) {
console.log('索引已存在,跳过创建索引步骤');
} else {
// 如果索引不存在,则创建新索引
console.log('创建索引...');
// 调用创建索引API
await milvusClient.createIndex({
collection_name: 'user_collection',
field_name: 'feature_vector',
index_type: 'IVF_FLAT',
metric_type: 'L2',
params: { nlist: 1024 }
});
// 输出索引创建成功的信息
console.log('索引创建成功');
}
// 输出加载集合到内存的信息
console.log('加载集合到内存...');
// 将集合加载到内存中
await milvusClient.loadCollection({
collection_name: 'user_collection'
});
// 输出集合加载成功的信息
console.log('集合加载成功');
} catch (error) {
// 捕获并输出操作失败的错误信息
console.error('操作失败:', error.message || error);
} finally {
// 无论成功与否,最终都关闭与Milvus的连接
await milvusClient.closeConnection();
// 输出关闭连接的信息
console.log('已关闭与Milvus服务器的连接');
// 退出程序
process.exit(0);
}
})();
4.5 集合管理 #
// 导入Milvus客户端库
const { MilvusClient } = require('@zilliz/milvus2-sdk-node');
// 创建Milvus客户端实例,配置连接地址和超时时间
const milvusClient = new MilvusClient({
address: 'localhost:19530',
timeout: 10000,
});
// 使用立即执行的异步函数管理集合
(async function manageCollection() {
try {
// 切换到指定的数据库
await milvusClient.useDatabase({
db_name: 'my_database'
});
// 检查集合是否存在
const { value: collectionExists } = await milvusClient.hasCollection({
collection_name: 'user_collection'
});
// 输出集合存在状态
console.log('集合是否存在:', collectionExists);
// 如果集合不存在,则退出函数
if (!collectionExists) {
console.log('集合不存在,无法执行后续操作');
return;
}
// 获取集合的详细信息
const collectionInfo = await milvusClient.describeCollection({
collection_name: 'user_collection'
});
// 输出集合详细信息
console.log('集合信息:', JSON.stringify(collectionInfo, null, 2));
// 获取集合的统计信息
const stats = await milvusClient.getCollectionStatistics({
collection_name: 'user_collection'
});
// 输出集合统计信息
console.log('集合统计信息:', stats);
// 获取所有集合的列表
const { collection_names } = await milvusClient.listCollections();
// 输出所有集合列表
console.log('所有集合列表:', collection_names);
// 以下代码被注释,用于从内存中释放集合
//await milvusClient.releaseCollection({
// collection_name: 'user_collection'
//});
//console.log('集合已从内存释放');
// 以下代码被注释,用于删除集合
//await milvusClient.dropCollection({
// collection_name: 'user_collection'
//});
//console.log('集合已删除');
} catch (error) {
// 捕获并输出操作失败的错误信息
console.error('操作失败:', error.message || error);
} finally {
// 无论成功与否,最终都关闭与Milvus的连接
await milvusClient.closeConnection();
// 输出关闭连接的信息
console.log('已关闭与Milvus服务器的连接');
// 退出程序
process.exit(0);
}
})();
4.6 数据管理 #
// 导入Milvus客户端库
const { MilvusClient } = require('@zilliz/milvus2-sdk-node');
// 创建Milvus客户端实例,配置连接地址和超时时间
const milvusClient = new MilvusClient({
address: 'localhost:19530',
timeout: 10000,
});
// 使用立即执行的异步函数管理数据
(async function manageData() {
try {
// 切换到指定的数据库
await milvusClient.useDatabase({
db_name: 'my_database'
});
// 检查集合是否存在
const { value: collectionExists } = await milvusClient.hasCollection({
collection_name: 'user_collection'
});
// 如果集合不存在,则退出函数
if (!collectionExists) {
console.log('集合不存在,无法执行数据操作');
return;
}
// 向集合中插入数据
const insertResult = await milvusClient.insert({
collection_name: 'user_collection',
fields_data: [
{
id: 1,
name: '张三',
feature_vector: [0.1, 0.2, 0.3]
},
{
id: 2,
name: '李四',
feature_vector: [0.4, 0.5, 0.6]
}
]
});
// 输出插入数据成功的信息
console.log('插入数据成功:', insertResult);
// 执行upsert操作(存在则更新,不存在则插入)
const upsertResult = await milvusClient.upsert({
collection_name: 'user_collection',
fields_data: [
{
id: 1,
name: '张三2',
feature_vector: [0.1, 0.2, 0.3]
},
{
id: 2,
name: '李四2',
feature_vector: [0.4, 0.5, 0.6]
},
{
id: 3,
name: '王五',
feature_vector: [0.7, 0.8, 0.9]
}
]
});
// 输出upsert操作成功的信息
console.log('upsert数据成功:', upsertResult);
// 删除指定ID的数据
const deleteResult = await milvusClient.delete({
collection_name: 'user_collection',
filter: 'id in [1, 2]'
});
// 输出删除数据成功的信息
console.log('删除数据成功:', deleteResult);
} catch (error) {
// 捕获并输出操作失败的错误信息
console.error('操作失败:', error.message || error);
} finally {
// 无论成功与否,最终都关闭与Milvus的连接
await milvusClient.closeConnection();
// 输出关闭连接的信息
console.log('已关闭与Milvus服务器的连接');
// 退出程序
process.exit(0);
}
})();
4.7 搜索 #
// 导入Milvus客户端库
const { MilvusClient } = require('@zilliz/milvus2-sdk-node');
// 创建Milvus客户端实例,配置连接地址和超时时间
const milvusClient = new MilvusClient({
address: 'localhost:19530',
timeout: 10000,
});
// 使用立即执行的异步函数管理数据
(async function manageData() {
try {
// 切换到指定的数据库
await milvusClient.useDatabase({
db_name: 'my_database'
});
// 执行向量搜索
const searchResult = await milvusClient.search({
collection_name: 'user_collection',
vector: [0.1, 0.2, 0.3], // 查询向量
field_name: 'feature_vector',
limit: 10, // 返回前10个最相似的结果
metric_type: 'L2', // 使用L2距离(欧氏距离),而不是余弦相似度
params: { nprobe: 10 }, // 搜索参数
output_fields: ['name'] // 返回的字段
});
console.log(searchResult);
} catch (error) {
// 捕获并输出操作失败的错误信息
console.error('操作失败:', error.message || error);
} finally {
// 无论成功与否,最终都关闭与Milvus的连接
await milvusClient.closeConnection();
// 输出关闭连接的信息
console.log('已关闭与Milvus服务器的连接');
// 退出程序
process.exit(0);
}
})();
5.参考 #
5.1. 正切函数 #
5.2 反正切函数 #
5.3 metric_type #
metric_type(度量类型)这个设置决定了系统如何计算两个向量之间的"相似度"。想象一下,这就像是测量两个人之间的"相似程度"的不同方法。
5.4 向量归一化 #
向量归一化是一种将向量转换为单位向量的过程。单位向量是指长度为1的向量,它们在多维空间中保持方向不变,但大小为1。
5.5.nprobe #
nprobe 是在向量数据库中进行近似最近邻搜索时的一个关键参数,它决定了搜索时要检查的聚类(或称"桶")的数量。
用生活例子来理解
想象一个大型图书馆:
- 图书馆里的书按主题分类放在不同的书架上(这些书架就像"聚类")
- 当你想找一本特定的书时,你可以:
- 只去看最可能有这本书的书架(nprobe 较小)
- 或者去看多个相关书架(nprobe 较大)
nprobe 的作用
当 nprobe 值增大时:
- ✅ 搜索结果更准确(因为检查了更多可能的区域)
- ❌ 搜索速度变慢(因为需要检查更多数据)
当 nprobe 值减小时:
- ✅ 搜索速度更快(因为只检查少量区域)
- ❌ 搜索结果可能不够准确(可能错过一些相关结果)
nprobe 的选择建议
- 小数据集:可以使用较大的 nprobe(如 10-30)
- 大数据集:需要平衡准确性和速度,可能从较小值开始(如 1-5)
- 实时应用:使用较小的 nprobe 保证速度
- 离线分析:可以使用较大的 nprobe 提高准确性